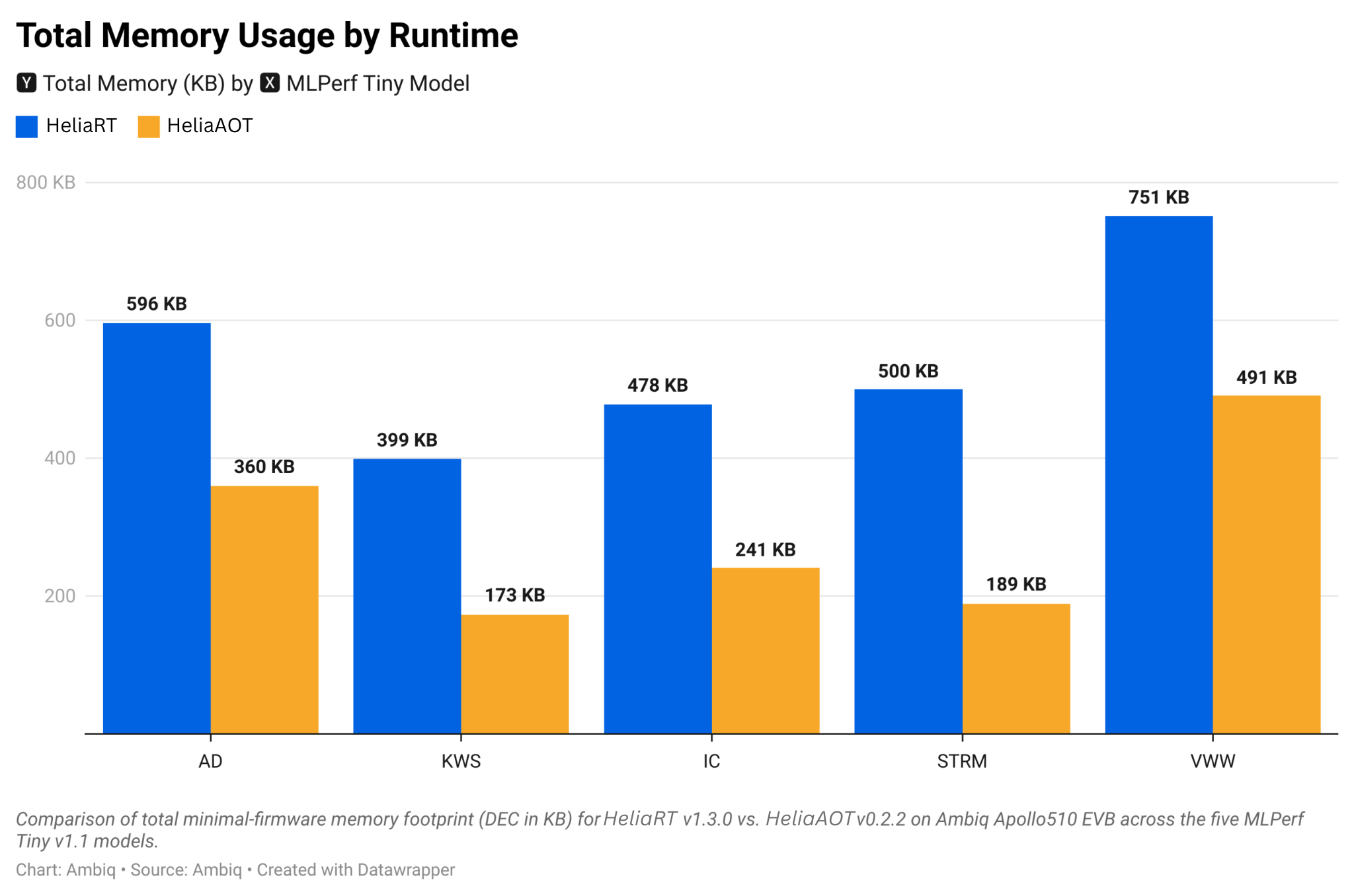
heliaAOT
Blazing Fast Neural Inferencing

heliaAOT is an ahead-of-time compiler that converts LiteRT models into highly optimized, standalone C inference modules—custom-tailored for Ambiq’s ultra-low-power SoCs. It produces compact, efficient, and human-readable C code with zero runtime overhead, enabling lightning-fast, power-efficient AI at the edge.