Our last blog post introduced the distinction between AI models that use language to understand what you’re saying and models that get the ‘gist’ of your speech. In today’s post, we’ll dig into the latter.
“OK, Computer”
Today, we’re all familiar with the predominant way of interacting with speech AI: the trigger phrase. “Hey Siri” and “Hey Alexa” have become part of our daily lives.
The folks who came up with this approach were trying to solve two problems: first, they needed an unambiguous way to determine when a user was addressing the AI, and second, they needed the AI to always listen for commands responsively but efficiently, which requires a lot of AI horsepower. “OK, computer” is not a natural language pattern, but it is easy to implement using AI; ideally, we should be able to speak to an AI as we would to a smart human assistant, trusting them to know when we’re speaking based on context, not only when we explicitly say their name. Keyword triggers were created to get around AI and power limitations that are no longer as relevant.
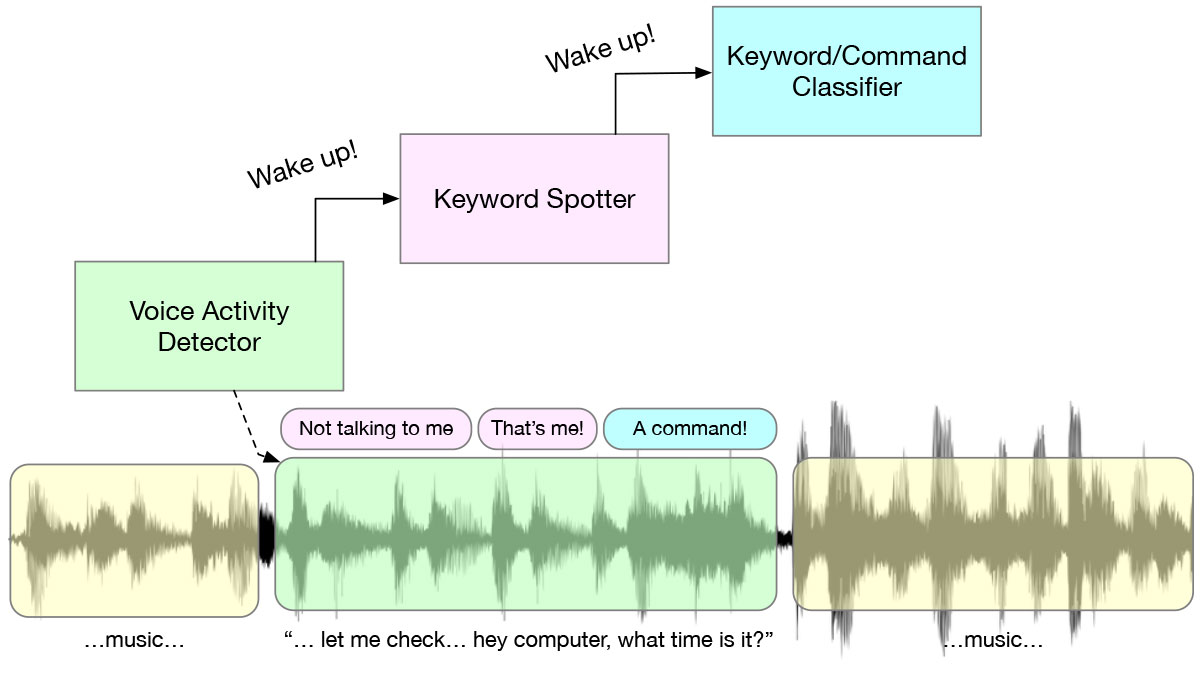
What happens behind the scenes when you say a keyword is an interesting multi-stage wakeup system, a cascade of algorithms and AI models designed to save power. Starting from a voice activity detector (VAD) which is always listening, the KWS model is triggered when any speech is present, and detect whether the speech is the pre-defined keyphrase, such as “Hey Alexa.” Only after all this happens will the more complex processing occur. This cascade is in place for power efficiency – at each stage, you execute the least demanding algorithm possible.
“When all you have is a hammer…”
There are many neural network approaches for keyword spotting, but (for me at least) the most interesting ones are based on recognizing spectrographic signatures. Spectrograms are pictures of audio translated into the frequency domain, and AI is very good at classifying pictures. Training an AI image classification model to recognize cats involves showing lots of pictures of cats. Training a keyword spotter is conceptually the same: record thousands of examples of people saying the phrase, calculate the spectrogram (basically an image) for each one and train the model to recognize those images.
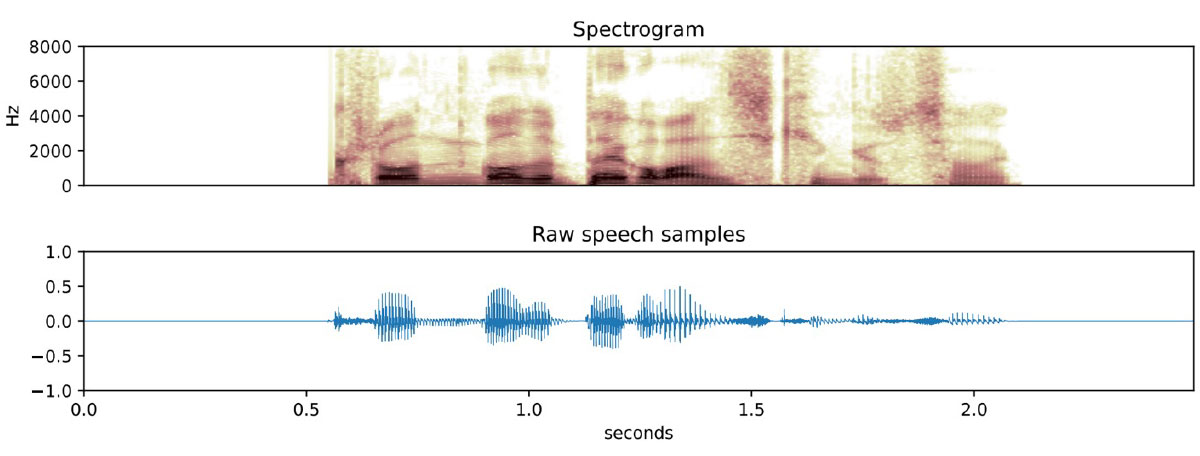
There are limitations to this approach, the most important one being that the audio can’t be very long. A spectrogram captures the frequencies of a snippet of audio over a fixed set of time – make the time too long, and responsiveness and accuracy drop. This means that this approach is suitable for two to five-second phrases but not for tasks requiring longer sentences.
Image classification is one of the oldest and best understood AI tasks, so it makes sense to leverage that class of algorithms. Many characteristics of image classification translate to audio as well. Most usefully, neural networks can be designed to learn ‘pattern matching’ separately from ‘the pattern being matched,’ which in practical terms means using transfer learning to teach the AI a new phrase instead of starting from scratch.
“Do what I mean, not what I say”
It turns out that once you start treating audio as images, you can train your AI to do much more than simple wake-words. The next logical step is to train your model on many command words, which can be used to create simple user interfaces, like when you say ‘navigation’ to turn on your car’s navigation system.
In fact, we can do much more than simple commands. Some models infer a speaker’s intention from a spoken phrase. These Speech-to-Intent models are trained on thousands of variations of a few dozen phrases and can generalize to variations that it has never heard before. These models are incredibly useful for creating speech-based user interfaces, finally allowing devices to break free of the usual fix-phrasing interface.
Practical Matters
Apollo4, with its ultra-low-power, 192Mhz performance, hyper-efficient audio peripherals, 2MB MRAM, generous cache, and large tightly-coupled-memory, is very well suited to running AI models such as KWS and speech-to-intent. Model sizes vary depending on the number of keywords or intents but generally fit in under 200KB of RAM and sip around 500 uJ per inference. Inference latency is not a factor at all, being well under the phrase length – KWS takes about 50ms, for example.
Speech recognition based on deep language models is further out, though steady progress on both the algorithmic and device sides will make this practical in the next year or two.
The Holy Grail
As we wrote above, most AI-based speech user interfaces are clunky, designed around engineering constraints rather than user needs, leading Alexa or Siri users to stick to well-worn simple commands such as ‘start timer’ and ‘raise volume.’
There will come a day when speaking to your watch will be little different than talking to a person: your device will know, based on all kinds of contextual information, whether you are speaking to it or an actual person, and instead of demanding that you memorize a few key phrases, it will learn to read your intentions, as a good personal assistant would.


