AI is a very memory-intensive application. Fortunately, Ambiq’s Apollo4 Plus has plenty of memory types and configurations to choose from. Deciding which memory to use and how to use it may require a bit of experimentation. Therefore, we ran some experiments with results for your consideration. As you’ll see below, there are many great options available to help meet your design requirements.
How AI Uses Memory
A deep learning AI model consists of a series of layers, each of which comprises many so-called ‘neurons.’ Individually, these neurons are simple: they take an input value and multiply it by a ‘weight’ associated with that particular neuron. The neuron with the weight proceeds to apply an ‘activation function’ to the combination, which is then fed to the next layer. For a trained model, the weights are static – they never change.
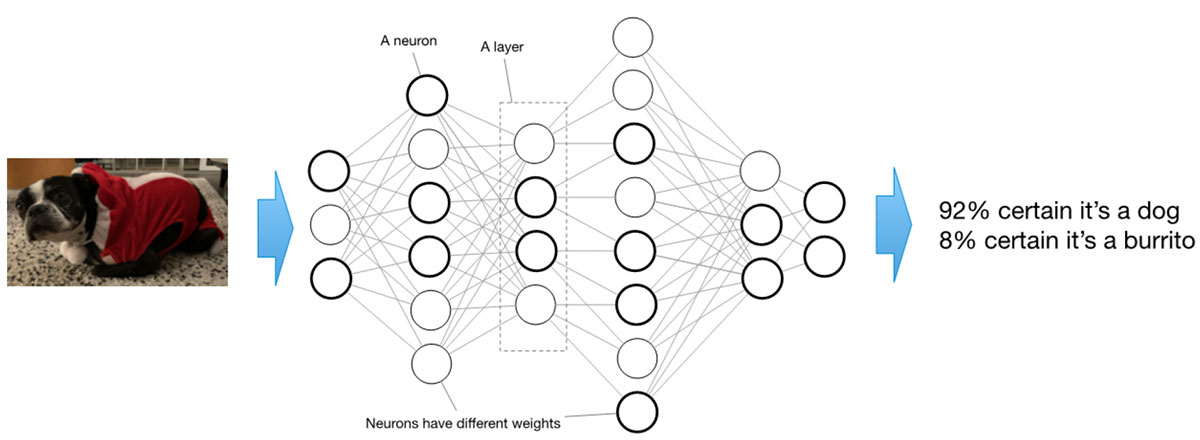
Admittedly, this description is woefully oversimplified. Nevertheless, it does shows that AI model memory utilization consist of two parts: a static part and a dynamic part. The static part represents the weights. The dynamic part consists of the values flowing through the neurons based on those weights, which is also known as ‘activations.’ We’ll use these facts as we explore how to optimize the AI model for the Apollo4 Plus’ memory configurations.
TensorFlow1 Lite for microcontrollers is a runtime interpreter that runs data through an AI model, performing the operations described above millions of times for every inference. The microcontroller’s memory architecture mirrors the weights and activations memory types required for running the AI model. A model’s weights, defined as the parameters (including trainable and non-trainable) used in the layers of the model, are stored in a model array (a collection of multiple model objects for storing and analysis.) A model’s activations are stored in the so-called the ‘TensorFlow Arena’. We can control where our compilation process places these memory objects using compiler directives. For example, this is how we control placement in the AmbiqSuite SDK:

The Apollo4 Plus Memories
The Apollo4 Plus SoC offers three types of memory we can use for AI: MRAM, tightly-coupled memory (TCM), and SSRAM. MRAM is a highly efficient non-volatile memory meant primarily for storing static values. TCM is high performance read/write memory that, as the name implies, tightly coupled to the CPU. SSRAM is general purpose read/write memory that is ‘further’ from the CPU. Accessing each of these memories has varying power and performance impacts.
The Experiment
TensorFlow’s performance is known to be very difficult to predict. Therefore, performing experiments is an easier approach. For our experiment, we ran MLPerf2 Tiny Inference’s keyword spotting (KWS) Benchmark. We leveraged the Benchmark’s sophisticated system for measuring performance and power utilization to empirically determine the impact of various memory allocation approaches. Specifically, we tried the following configurations:
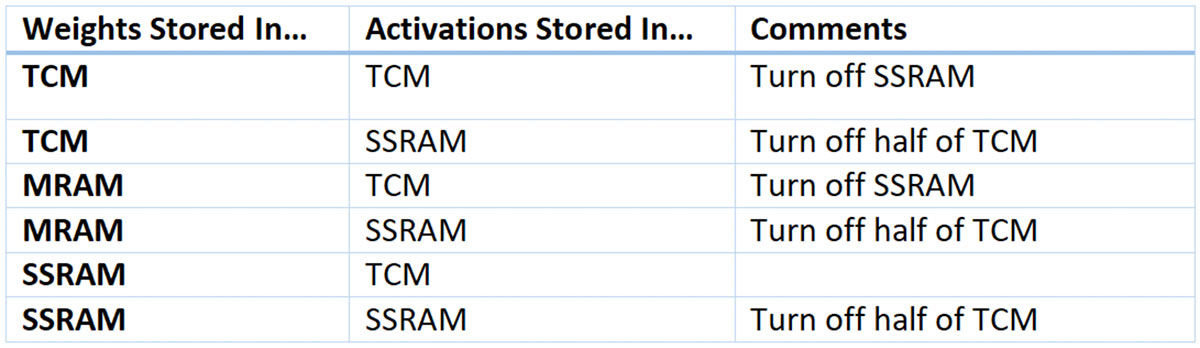
A few important points to note:
- We never store activations in the MRAM as activations are dynamic, and MRAM likes to be static
- We turn off any memory we aren’t using
The Results
The following chart shows the measured results for each experiment, relative to our chosen baseline of everything running in TCM. We use the axis scale to exaggerate the differences between the experiments. In reality, any one of these combinations is more than suitable for running keyword spotting on IoT edge devices.
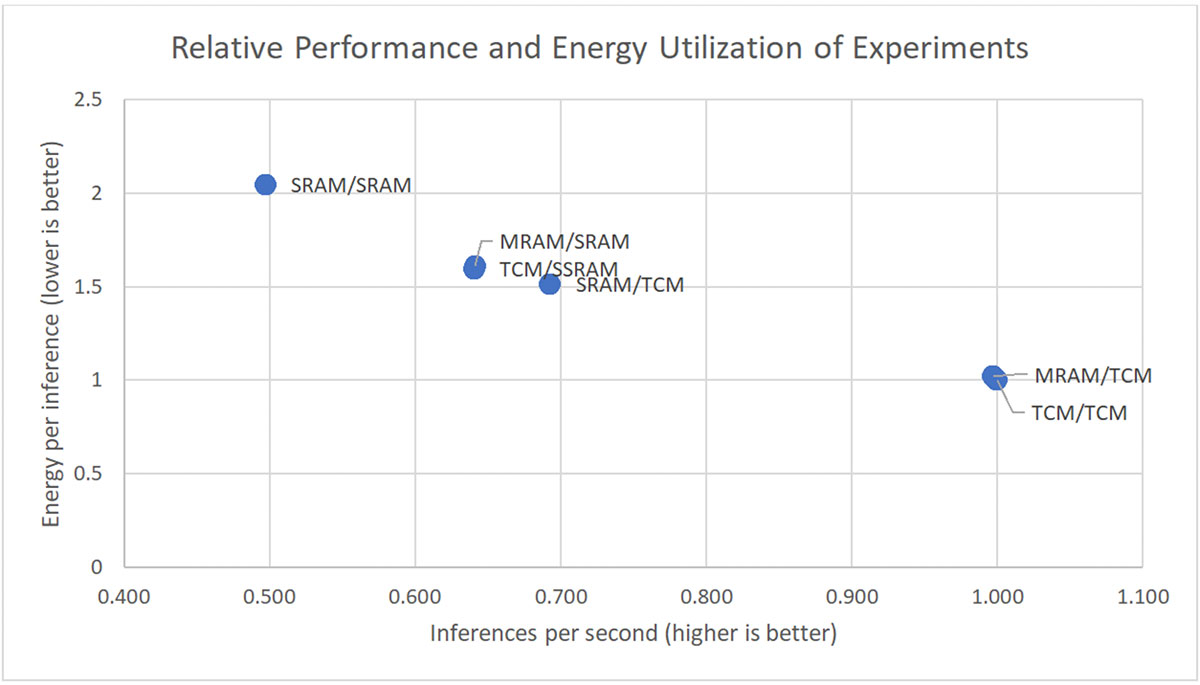
We can see that the MRAM offers outstanding performance and energy efficiency when coupled with TCM or SSRAM.
Conclusions
AI requires significant memory, both static and dynamic. In real life applications, however, AI must share the memory with the rest of the applications. The Apollo4 Plus offers many options to the AI developers, both in terms of memory type and memory configuration. In the aforementioned experiences, developers wishing to offer the most optimized performance and energy efficiency can place weights in Apollo4’s capacious 2MB MRAM and activations in TCM with little impact. However, no matter what configuration the developer chooses, our SPOT-enabled platform3 will consistently and reliably deliver immense performance with outstanding power efficiency.
1 TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
2 MLPerf is a consortium of AI leaders from academia, research labs, and industry whose mission is to “build fair and useful benchmarks” that provide unbiased evaluations of training and inference performance for hardware, software, and services—all conducted under prescribed conditions. https://mlcommons.org/en/policies/
3 SPOT®, Subthreshold Power Optimized Technology, is a proprietary technology platform by Ambiq®. It revolutionizes the possibilities of edge AI by delivering the world’s most energy-efficient solutions available on the market.


